












-
随着我国城市城镇化加速,新旧建筑的更迭也不断加快,导致建筑垃圾数量增长迅速。建筑垃圾对环境造成了巨大危害,因此建筑垃圾的回收与利用对环境保护具有重要的意义。目前堆放和填埋作为主要处理建筑垃圾的方式,资源回收率低,环境危害大。建筑业作为碳排放最高的三大行业之一,节能减排的任务迫在眉睫。我国对建筑垃圾的处理方式相对单一,建筑垃圾的处理方式主要是采用不分拣直接处理的方式,多种建筑垃圾混杂在一起,造成利用率变低、资源浪费。目前,已有企业开始对建筑垃圾中混凝土块进行回收,然后粉碎用于建筑施工、路面铺设中,有效促进了资源回收利用。然而建筑垃圾中的砖块、泡沫板、塑料等垃圾直接影响到回收材料的使用性能,因此在回收生产过程中需要对其进行分拣。目前由于生产工况和成本的限制,生产线中通常采用传统人工分拣的方式。这种方式不仅效率低,而且垃圾处理生产线的环境较恶劣、粉尘较大,对人体身心健康有害。为此,针对建筑垃圾精准自动分拣的方法是一项值得研究的内容。
针对垃圾智能分类识别的研究,许多学者进行了深入探索。夏景明等[1]提出一种基于VGG16改进的轻量化垃圾分类网络模型LW-GCNet,将传统卷积替换为深度可分离卷积并添加SE注意力机制;原模型中的全连接层替换成自适应最大池化层和全局平均池化层。改进模型具有轻量化、识别准确率高等优势。赵冬娥等[2]利用光谱角填图法、主成成分分析法和Fisher判别分析建立了垃圾分类识别模型,实现了对高光谱图像中的垃圾进行分类识别。XIAO等[3]应用近红外高光谱技术对建筑垃圾进行提取和分类,为避免高光谱数据的冗余性,提出一种勾股小波变换 (PWT) 提取特征反射率的方法。同时,提出一种可以适应较恶劣的工作环境的互补故障排除方法 (CT) 用于在线识别建筑垃圾。赵珊等[4]提出一种基于改进SSD的垃圾分类检测模型,将隐式特征金字塔和MobileNetV2引入原始SSD模型得到改进模型,提升了模型检测精度的同时也加快了模型检测速度。ZHANG等[5]提出了一种基于ResNet18的垃圾分类模型 (CTR) ,通过在残差网络中加入了自监测模块,使得CTR模型可以整合所有通道映射的相关特征,压缩空间维度的特征,提高了特征图的表示能力,在TrashNet数据集上对该模型进行了测试,实验结果表明,该模型的图像分类达到较高的准确率。ZHANG等[6]提出了一种新的两阶段垃圾识别检测算法 (W2R) ,该算法分为训练识别模型 (RegM) 和通过语义检索构建识别检索模型 (RevM) 2个阶段。实验结果表明,由W2R算法训练的RevM的性能比一阶段分类模型 (ClfM) 和手动分拣实验 (MS) 更好且鲁棒性更高。高明等[7]提出了一种迁移学习网络架构GANet,并将GANet应用于垃圾分类识别中,将EfficientNet-B5作为主干网络;引入像素级空间注意力机制PSATT;应用RAdam优化方法、标签平滑正则化与Focal loss相结合的损失函数、改进的阶梯型OneCycle学习率控制法、SWA权重平滑等训练策略,GANet在云端部署测试中达到了较好的推理速度和较高的分类准确率。康庄等[8]提出了一种基于特征提取网络Inception v3和迁移学习相结合的方法,并将模型部署在树莓派3B+上,实现了对垃圾的自动分类回收。马雯等[9]将Faster R-CNN中特征提取网络VGG16替换为ResNet50,同时使用Soft-NMS算法代替原模型中非极大值抑制算法,得到一种改进的Faster R-CNN模型用于垃圾检测,改进模型对垃圾具有较高的检测精度。LIN等[10]提出了一种CVGGNet模型,即VGG结构 (VGGNet-11、VGGNet-13、VGGNet-16和VGGNet-19) 基于迁移学习,结合数据扩充和循环学习率对建筑垃圾进行分类。实验结果表明,循环学习率和迁移学习可以提高VGGNet的性能。NOWAKOWSKI[11]等利用卷积神经网络 (CNN) 对垃圾的类型进行分类,并利用区域卷积神经网络 (R-CNN) 检测垃圾的类别和大小,所采用的分类和检测算法均显示出较高的识别效率。此外,张睿萍等[12]将Mask R-CNN中特征提取主干网络ResNet替换为ResNeXt101得到改进模型,解决了垃圾多分类任务中分类检测效果不佳等问题。LU等[13]应用语义分割模型DeepLabv3+开发了建筑垃圾分割模型。邢洁洁等[14]将YOLOv5s模型进行了轻量化改进,并将改进模型部署到边缘计算机设备上应用于农田垃圾检测中。上述方法在不同程度上提升了垃圾分类检测的性能。建筑垃圾作为垃圾的一种,在分类检测方法上具有相通性,因此以上垃圾分类检测方法的提出为建筑垃圾分类检测的可行性提供了理论铺垫。
WANG等[15]提出了YOLOv7目标检测模型,并通过与以往目标检测模型检测性能进行对比,验证了YOLOv7具有更高的检测精度和更快的检测速度。由于建筑垃圾分拣任务中需要建筑垃圾分类检测算法具有较高的实时性和准确性,因此本研究选用YOLOv7作为基础模型对建筑垃圾进行分类检测。但由于建筑垃圾形状不规则且颜色差异大,故存在误检漏检的情况,因此本研究提出一种基于YOLOv7的改进模型DC-YOLOv7。本研究的创新点包括:1) 改进YOLOv7上采样模块,用CARAFE上采样算子替代最邻近插值上采样算子,提高了模型的检测精度,以实现对建筑垃圾的准确分类识别;2) 对YOLOv7模型进行轻量化设计,选用DSConv模块替换YOLOv7的Head中部分传统卷积,降低了模型计算量的大小,保持较高的分类检测速度;3) 将DC-YOLOv7模型应用在建筑垃圾分拣任务中,并通过实验验证了其有效性。
-
目前YOLOv7有7种不同的网络模型,针对边缘GPU设计了轻量级的YOLOv7-tiny模型;针对普通GPU设计了YOLOv7模型,然后通过对YOLOv7的深度和宽度进行缩放,又得到了YOLOv7-X模型;针对高性能云GPU设计了YOLOv7-W6模型,通过对YOLOv7-W6缩放得到了YOLOv7-E6和YOLOv7-D6两种模型,然后将E-ELAN用于YOLOv7-E6模型中,得到了YOLOv7-E6E模型[15]。在建筑垃圾分拣生产线上,权衡模型检测性能和成本等问题,建筑垃圾分类检测模型主要部署在普通GPU服务器中,因此本研究不再讨论适用于云GPU的YOLOv7-W6、E6、D6和E6E四种模型。虽然YOLOv7-tiny模型是面向边缘GPU部署而设计的,但也可部署在普通GPU上。因此对于普通GPU服务器,YOLOv7-tiny、YOLOv7与YOLOv7-X三种模型均可适用。为对比三者的检测性能,选择在Microsoft COCO通用数据集上训练三种模型,检测性能和参数对比结果见表1。从表1可知,YOLOv7-tiny比YOLOv7的参数量和FLOPs分别低29.3M、90.8G,检测速度每秒快123帧,但是mAP值却比YOLOv7低14.6个百分点。YOLOv7-X比YOLOv7的mAP值虽然高1.3个百分点,但是模型的参数量和FLOPs分别比YOLOv7高32.8M、85.2G,检测速度也每秒慢35帧。综合考虑网络检测精度、速度和轻量化要求后,结合模型应用场景,本研究选择YOLOv7作为基础模型,并对其进行优化,以实现建筑垃圾的分类检测。
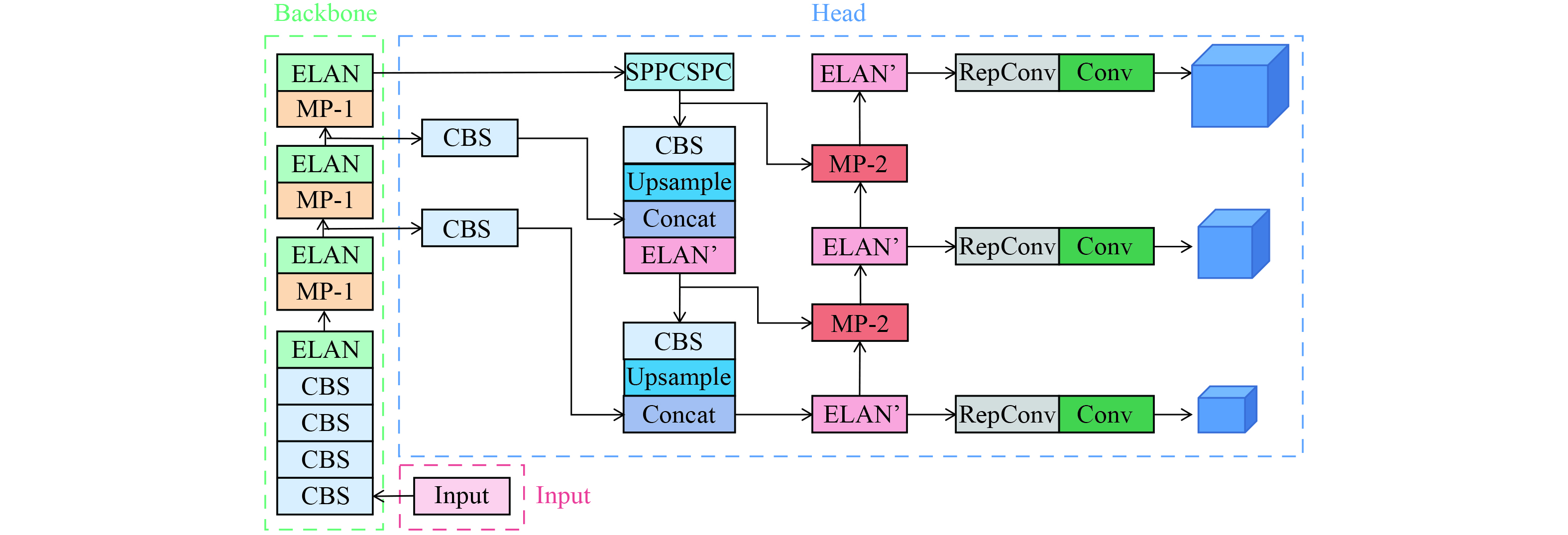
YOLOv7模型主要由输入 (Input) 、主干网络 (Backbone) 和头部网络 (Head) 三部分组成[16]。其主干网络是由CBS、ELAN和MP-1等模块组成,头部网络是由CBS、Conv、Upsample、SPPCSPC、MP-2、ELAN’和RepConv等模块组成。YOLOv7模型结构如图1所示。输入图像经过一系列数据预处理后通过输入模块把尺寸缩放至固定尺寸,随后进入主干网络 (Backbone) 提取图像特征,将图像特征送入头部网络 (Head) 中进行特征融合,得到大、中、小3种尺寸的特征,最后将融合后的特征送入到检测头,输出检测结果。
在YOLOv7模型中,CBS模块由卷积、批量归一化和SiLU激活函数组成[17]。ELAN和ELAN’模块通过控制梯度路径,使模型学习到更多的特征。SPPCSPC模块通过增大感受野,使算法适应不同分辨率的图像。MP-1和MP-2模块主要作用是执行下采样。UPSample模块是上采样的模块,它使用的上采样方式是最近邻插值法。RepConv模块作用是对不同尺度特征进行通道数调整[16]。YOLOv7部分基础组件结构如图2所示。
-
YOLOv7中的上采样模块使用的是最邻近插值算法,该算法不需要计算,只需将距待求像素点最近的像素灰度值赋值给它。最邻近插值法具有计算量小、计算简单等优点,但由于未考虑周围像素点的影响,采样后损失了图像的质量,图像失真严重。
考虑到周围像素点影响,减少图像质量的损失,使用可在更大感受野内聚合上下文信息的CARAFE模块替换YOLOv7中最邻近插值算法的上采样模块;为提高模型精度的同时保持模型的轻量化,同时,引入DSConv模块对YOLOv7中Head部分进行轻量化改进,由于DSConv中采用整数运算,因而实现了内存使用量的减少并提高运算速度。最终改进的模型名称取自DSConv和CARAFE的首字母并结合YOLOv7,称为DC-YOLOv7。DC-YOLOv7的模型结构如图3所示,其改进组件结构图如图4所示。
1) CARAFE上采样算子
CARAFE是轻量级上采样算子,在重组的时候可以有较大的感受野,能更好地利用周围的信息,会根据输入特征来指导重组过程,且不会引入过多的参数和计算量。在不同的任务中,使用CARAFE上采样算子的模型的检测效果都取得了明显提升,同时其带来少量额外参数和计算量。
CARAFE算子主要由上采样核预测模块和特征重组模块组成,其结构图见文献[18]。输入特征图
$ x $ ,其大小为$ C \times H \times W $ ,首先上采样核预测模块会预测每个位置上的上采样核,然后特征重组模块会完成上采样操作,得到输出特征图$ {x'} $ ,其大小为$ C \times \sigma H \times \sigma W $ ,$ {x'} $ 中任意目标位置$ {l'} = ({i'},{j'}) $ 与x中的源位置$ l = (i,j) $ 是一一对应的,其中$ \sigma $ 为上采样率,$ i = {i'}/\sigma $ ,$ j = {j'}/\sigma $ 。上采样核预测模块主要完成特征图通道压缩、内容编码及上采样核预测、上采样归一化三个步骤。为了减少后续的计算量,对于形状为
$ C \times H \times W $ 的输入特征图,通过$ 1 \times 1 $ 卷积将它的通道数压缩到$ {C_{\text{m}}} $ ,假设上采样核尺寸为$ {K_{{\text{up}}}} \times {K_{{\text{up}}}} $ ,对于压缩后的特征图使用$ {K_{{\text{encoder}}}} \times {K_{{\text{encoder}}}} $ 的卷积预测上采样核,将通道维在空间维展开得到上采样核,其形状为$ K_{{\text{up}}}^2 \times \sigma H \times \sigma W $ ,随后通过softmax对上采样核进行归一化操作[19]。其每个目标位置$ {l'} $ 的上采样核$ {w_{l'}} $ 由上采样核预测模块$ \psi $ 基于$ {x_l} $ 的邻域来预测,如式(1)所示。特征重组模块会将
$ {x'} $ 中所有位置都映射到$ x $ 中,以目标位置为中心,取大小为$ {K_{{\text{up}}}} \times {K_{{\text{up}}}} $ 的区域,将$ {K_{{\text{up}}}} \times {K_{{\text{up}}}} $ 与该点预测的上采样核做点积运算得到输出,重组过程如式(2)所示,其中$ \phi $ 是将$ {x_l} $ 的邻域与上采样核$ {w_{l'}} $ 进行重组的内容感知模块。式中:
$ N({x_l},k) $ 表示以$ l $ 为中心$ x $ 的$ k \times k $ 区域。2) DSConv分布偏移卷积
DSConv称为分布偏移卷积,其总体目标是通过使用量化和分布偏移来模拟卷积层的行为,DSConv相较于传统卷积,其内存使用量更低、计算速度更快。DSConv将传统的卷积内核分解为可变量化内核 (VQK) 和分布偏移,VQK仅保存可变位长整数值,它具有与原始卷积张量相同的大小
$ ({C_{\text{o}}},{C_{\text{i}}},{K_{\text{h}}},{K_{\text{w}}}) $ ,其中$ {C_{\text{o}}} $ 是下一层的通道数,$ {C_{\text{i}}} $ 是当前层中的通道,$ {K_{\text{h}}} $ 和$ {K_{\text{w}}} $ 分别是内核的宽度和高度。分布偏移由两个分布移位器张量组成,包括内核中的分布偏移 (KDS) 和通道中的分布偏移 (CDS) ,通过应用KDS和CDS移动VQK,使DSConv的输出和原始权重张量的值相匹配。在DSConv的量化过程中,VQK和每块尾数张量 (Mantissa Tensor) 进行点积运算,KDS和原始卷积的指数张量(Exponent Tensor)数值进行相加运算,将点积运算结果与相加运算结果进行点积运算,得到最终输出结果。DSConv的量化过程结构图见文献[20]。
在量化过程中,首先需要对每个卷积层权重进行缩放,将所有的权重量化到最接近的整数
$ {w_q} $ 并放到VQK中,$ {w_q} $ 的范围如式(3)所示。式中:
$ {w_q} $ 是张量中的参数值;b是网络输入位数。随后,KDS需要将VQK匹配原始的卷积张量,KDS用两个张量在两个域中移动来做到这一点,在这一过程中,对两个张量进行初始化,采用最小化相对熵的方法,求出原始权重分布和KDS之间最小的信息损失。通过位移后的VQK和原始分布的softmax值来计算
$ \xi $ ($ \xi $ 为该块的KDS值) ,如式(4)所示。上述公式中位移后的VQK和原始分布的softmax值分别如式(5)、式(6)所示。
式中:j为当前层的第j块卷积核;i为第i层卷积;
$ \hat \xi $ 为偏差,默认为0;$ {T_j} $ 为当前第j块的VQK的初始值;$ {I_j} $ 为当前第j块的softmax值。通过上述方法得到了KDS和VQK,从而实现了对原始卷积的量化。
-
本实验基于Windows11操作系统,采用Python3.7.6编程语言,Pytorch1.11.0深度学习框架。实验相关硬件配置及模型参数如表2所示。
-
本实验采用自制的建筑垃圾数据集,实验数据集图片示例如图5所示。数据集采集于不同光照条件和不同角度下,共采集了砖、泡沫板、塑料3类建筑垃圾图片,其中包含不同建筑垃圾相互堆叠的图片 (见图5(d)) ,每类采集了约200张RGB图片,共约800张,分辨率均为640×640像素。本实验以7∶1∶2的比例划分的训练集、验证集和测试集。在该数据集上进行对比实验,训练并验证改进模型的有效性。
-
本实验使用精确率P(Precision)、召回率R(Recall)、平均精度均值mAP(mean Average Precision)、每秒检测帧数FPS(Frame Per Second)、参数量Params和反应模型复杂度的计算量FLOPs作为评价指标,来衡量建筑垃圾的检测效果[21]。
1) 精确率P表示预测的正样本有多少是预测正确的,如式(7)所示。
2) 召回率R表示样本中的正样本有多少是预测正确的[22],如式(8)所示。
上述两式中:针对每类建筑垃圾,FP表示误检的建筑垃圾个数,个;TP表示检测正确的建筑垃圾的个数,个;FN表示漏检的建筑垃圾个数,个。
3) mAP指所有类别建筑垃圾的平均精度AP(Average Precision)的均值。在坐标系中,AP可由计算P-R曲线围成的面积得到,AP衡量的是训练模型在每个类别上的检测效果,如式(9)所示。
在多类别识别的目标检测任务中,常使用mAP指标。本研究使用的mAP是IoU阈值为0.5时得到的,它也被称为mAP@.5,该评价指标常用于评价目标检测模型的整体检测性能,mAP越高表示目标检测网络模型整体效果越好,如式(10)所示。
式中:c为数据集中的总类别数;i为检测次数。
4) FPS表示目标检测网络每秒检测图片的数量,常用来评估目标检测的速度,如式(11)所示。
式中:FrameCount为检测图片的总数,帧;ElapsedTime为检测图片的总时长,s。
5) 参数量Params表示模型中包含的所有参数总量,用来衡量模型的大小 (空间复杂度) ,单位为M。
6) 计算量FLOPs用来衡量算法的复杂度 (计算时间复杂度) ,单位为G。
-
为了研究CARAFE上采样算子中
$ {K_{{\text{encoder}}}} $ 和$ {K_{{\text{up}}}} $ 值的改变对改进YOLOv7模型性能的影响,在建筑垃圾数据集上进行对比实验,实验结果见表3。从实验结果可以看出增加$ {K_{{\text{up}}}} $ 的同时也需要更大的$ {K_{{\text{encoder}}}} $ ,因为内容编码器需要更大的感受野来预测更大的重组内核。本实验主要对比mAP值,总体来说,同时增加$ {K_{{\text{encoder}}}} $ 和$ {K_{{\text{up}}}} $ 可以提高性能,而仅增加其中之一则不会提高性能。通过实验结果可以总结出公式$ {K_{{\text{encoder}}}} = {K_{{\text{up}}}} - 2 $ ,与文献[18]中得出的结论一致,按照这个公式设置$ {K_{{\text{encoder}}}} $ 和$ {K_{{\text{up}}}} $ 值得到的模型效果更佳。为了权衡模型检测精度和检测速度之间的关系,在后续实验中,CARAFE上采样算子中的$ {K_{{\text{encoder}}}} $ 和$ {K_{{\text{up}}}} $ 的值折中设置为$ {K_{{\text{encoder}}}} = 3 $ 和$ {K_{{\text{up}}}} = 5 $ 。为了验证本研究提出的网络模型 (DC-YOLOv7) 改进的效果,在建筑垃圾数据集上进行消融实验, 将DC-YOLOv7与YOLOv7和改进模型Ⅰ进行对比。改进模型Ⅰ是在YOLOv7的基础上引入了CARAFE算子。为保证实验的准确性,模型训练的过程中均采用相同的参数,实验结果见表4。
通过表4可以看出,在YOLOv7中引入CARAFE上采样算子,对比YOLOv7网络模型,虽然模型的整体参数量略有增加,改进模型I比YOLOv7的参数量增加了0.3%,计算量增加了0.2%,但是mAP值得到大幅度提升,提升了2.6%,验证了CARAFE对模型精度提升的优越性。同时,在YOLOv7中Head部分引入DSConv模块后, 与YOLOv7对比,DC-YOLOv7的mAP值提升了2.3%,计算量降低了8.7%,这表明DC-YOLOv7既提高了检测精度又保持着模型的轻量化。此外,由于引进的DSConv模块不如原始卷积模块提取的特征丰富,降低了特征提取的精准度,因而DC-YOLOv7略低于改进模型I的mAP值。相较于YOLOv7,虽然mAP值提升的少一些,但是DC-YOLOv7更加轻量化,便于部署。总体而言,该实验验证了将CARAFE上采样算子和DSConv模块组合使用在YOLOv7网络模型中的有效性。
在测试集中选取了5张建筑垃圾的图片,分别使用YOLOv7模型、改进模型I和DC-YOLOv7模型3种网络模型对建筑垃圾图片进行目标检测,不同模型的检测效果如图6所示,其中图6第⑤行为不同建筑垃圾堆叠图片的检测结果。从检测结果图中可以看出, 与YOLOv7相比,改进模型I和DC-YOLOv7的漏检率和错检率均有降低,如YOLOv7漏检了图6第①行中的泡沫板、图6⑤行中的塑料,但两张图中漏检的目标均被改进模型I和DC-YOLOv7成功检测出来。在图6第②行中YOLOv7将光线误检成了泡沫板,在图6第③行和图6第④行中YOLOv7也发生了误检的情况,这些误检的目标均被改进模型I和DC-YOLOv7正确检出。由于图6第①行到图6第⑤行中受光照、相互遮挡、物体形状不规则且颜色有差异等问题的影响,会造成YOLOv7模型误检漏检的情况,但改进模型I和DC-YOLOv7模型则没有受这些问题的影响。可以看出改进模型I和DC-YOLOv7模型检测效果比较接近,相对于YOLOv7检测效果均有提升。因此,采用改进模型I和DC-YOLOv7模型可以检测出更准确的建筑垃圾类别信息,降低了漏检率和错检率的同时,置信度也更高。
-
为了验证改进模型DC-YOLOv7的检测速度,在建筑垃圾数据集上进行对比实验,对比Faster RCNN[23]、SSD[24]、RFBNet[25]、RetinaNet[26]、YOLOv7[15]等目标检测网络模型,实验结果如表5所示。
通过表5可以看出,DC-YOLOv7的检测速度能达到每秒50帧,这是由于其采用了DSConv模块来简化传统的卷积模块,使网络模型更加轻量化。DC-YOLOv7比SSD、RFBNet、RetinaNet模型的检测速度分别快了117.4%、100%、85.2%,这表明了DC-YOLOv7在实时检测速度上的优势。虽然DC-YOLOv7比YOLOv7网络模型的检测速度慢了16.7%,但也可以满足建筑垃圾实时检测任务的需求。
此外,在轻量化方面,DC-YOLOv7的参数量仅有35.6M,模型的计算复杂度为96G。与SSD、RFBNet和YOLOv7相比,虽然参数量分别高了11.6 M、0.1 M、0.1M,但模型的复杂度分别低了178.5 G、221.3 G、9.2G。相比于Faster RCNN、RetinaNet,DC-YOLOv7的参数量和计算复杂度均低于这两个模型的这两项指标,参数量分别低了101.2M和0.8M,计算复杂度分别低了305.8G和50.3G。综上所述,DC-YOLOv7足够轻量化,可以被部署在大部分硬件设备上。
-
本研究建筑垃圾分类检测算法主要应用在建筑垃圾回收与再利用企业的建筑垃圾分拣生产线中。在建筑垃圾传送过程中,基于本研究提出垃圾分类检测模型实现对非混凝土块的垃圾进行识别,将识别信息传递给自动分拣设备,完成建筑垃圾的分拣操作。为实现建筑垃圾中的钢筋高效分拣,生产线中通常采用磁铁吸附的方法。最后对分拣后的混凝土块进行粉碎,完成回收再利用。因此本研究只需要识别除了钢筋、混凝土块之外的其他建筑垃圾即可。为检测出更多类型的建筑垃圾,本研究增加对木块样本的训练。为验证对实际工况下建筑垃圾识别检测效果,本节选用实际工况下分别含砖块、泡沫板、塑料、木块等建筑垃圾的图像,并对四张图片中的建筑垃圾进行识别,算法识别检测结果如图7所示。由图7可知,本研究提出的建筑垃圾识别模型对于实际工况下的建筑垃圾具有较好的识别效果。
-
提出了一种基于改进YOLOv7的建筑垃圾检测模型DC-YOLOv7。相比于其他目标检测模型,改进模型更好地权衡了模型检测精度和模型性能之间的关系,在具有较高检测精度和检测速度的同时保持了模型的轻量化。引入CARAFE上采样算子替换了YOLOv7中最邻近插值方式的上采样算子,虽然带来了少量额外参数和计算量,但提升了模型的检测精度;在YOLOv7的Head网络部分引入DSConv模块替换部分传统卷积,由于DSConv模块中采用整数运算,因此,相比于传统卷积中的浮点运算,DSConv模块内存使用量更少、运算速度更快。在建筑垃圾测试集上测试,本研究提出的建筑垃圾检测模型DC-YOLOv7的mAP值达到了90.7%,检测速度可达到每秒50帧,计算量降至96G,综合性能高于常见的目标检测网络。该模型能够快速准确地检测出常见种类的建筑垃圾,克服了建筑垃圾形状不规则、颜色差异大等特征导致的精度低、检测速度慢等问题,可为提升建筑垃圾的回收和资源化利用提供技术支撑。
基于改进YOLOv7算法的建筑垃圾分类检测
Construction waste classification and detection algorithm based on improved YOLOv7
-
摘要: 基于深度学习算法的建筑垃圾分类检测技术对建筑垃圾回收和资源再利用具有重要意义。提出了改进的YOLOv7算法实现对建筑垃圾的分类检测。改进算法采用内容感知特征重组 (content-aware reassembly of features, CARAFE) 上采样算子替换YOLOv7中最邻近插值方式的上采样算子,从而提高了目标检测精度;引入分布移位卷积 (distribution shifting convolution, DSConv) 模块替换YOLOv7的头部网络中部分传统卷积,实现了模型的轻量化。结果表明,改进算法的mAP值达到了90.7%,模型计算量仅为96G。该方法具有准确率高、稳健性强等特点,在建筑垃圾分类检测实际场景中具有较高的应用价值。Abstract: The construction waste classification and detection technology based on deep learning algorithm is of great significance to the construction waste recycling and resource reuse. In this paper, the improved YOLOv7 algorithm was proposed to realize the classification and detection of construction waste. Firstly, the content aware reassembly of features (CARAFE) upsampling operator was used to replace the nearest interpolation upsampling operator in YOLOv7, which reduced the loss of image quality in the upsampling process and aggregates contextual information within a large receptive field, thereby improving the detection accuracy of construction waste. Secondly, the distribution shifting convolution (DSConv) module was introduced to replace the traditional convolution in the head network of YOLOv7, achieving lightweight of the model. The experimental results showed that the mAP value of the improved model reached 90.7%, and the computational complexity was only 96G. The improved model had higher accuracy and stronger robustness performance. It has high application value in the field of construction waste classification and detection.
-
Key words:
- construction waste detection /
- YOLOv7 /
- CARAFE /
- DSConv
-
-

图 7 实际工况下的模型检测效果
Figure 7. Detection effects of the proposed model under actual conditions
表 1 不同模型的检测性能和参数对比结果
Table 1. The detection performance and parameter comparison results of different models
模型 评价指标 mAP/% 参数量/M FLOPs/G FPS/ (帧·s−1) Yolov7-tiny 54.5 5.9 13.7 212 Yolov7 69.1 35.2 104.5 89 Yolov7-X 70.4 68.0 189.7 54  下载: 导出CSV
下载: 导出CSV
表 2 相关硬件配置及模型参数
Table 2. Related hardware configuration and model parameters
名称 配置 名称 数值 GPU RTX3060 图像大小/像素 640×640 CPU R7 5800H 学习率 0.01 CUDA(版本) 11.3 迭代次数 300 内存 16G 批量大小 4
下载: 导出CSV
表 3 不同
$ {K_{{\text{encoder}}}} $ $ {K_{{\text{up}}}} $ Table 3. Detection performance of the improved mode with different
$ {K_{{\text{encoder}}}} $ $ {K_{up}} $ $ {K_{{\text{encoder}}}} $ $ {K_{{\text{up}}}} $ P/% R/% mAP/% FPS/ (帧·s−1) 1 3 90.8 82.6 90.7 61 1 5 95.9 74.6 90.6 54 3 3 94.1 84.9 90.4 61 3 5 93.9 81.4 91.0 55 3 7 96.5 76.1 91.0 43 5 5 96.2 80.4 90.7 53 5 7 97.0 84.2 91.7 43
下载: 导出CSV
表 4 基于YOLOv7模型的消融实验
Table 4. Ablation experiment based on YOLOv7 model
网络模型 评价指标 Params/M FLOPs/G mAP/% YOLOv7 35.5 105.2 88.4 改进模型Ⅰ 35.6 105.4 91.0 DC-YOLOv7 35.6 96.0 90.7
下载: 导出CSV
表 5 不同网络模型性能对比结果
Table 5. Performance comparison results of different network models
网络模型 评价指标 Params/M FLOPs/G FPS/ (帧·s−1) Faster RCNN 136.8 401.8 10 SSD 24.0 274.5 23 RFBNet 35.5 317.3 25 RetinaNet 36.4 146.3 27 YOLOv7 35.5 105.2 60 DC-YOLOv7 35.6 96.0 50
下载: 导出CSV
-
[1] 夏景明, 徐子峰, 谈玲. 轻量化网络LW-GCNet在垃圾分类中的应用[J]. 环境工程, 2023, 41(2): 173-180. [2] 赵冬娥, 吴瑞, 赵宝国, 等. 高光谱成像的垃圾分类识别研究[J]. 光谱学与光谱分析, 2019, 39(3): 921-926. [3] XIAO W, YANG J H, FANG H Y, et al. A robust classification algorithm for separation of construction waste using NIR hyperspectral system[J]. Waste Management, 2019, 90: 1-9. doi: 10.1016/j.wasman.2019.04.036 [4] 赵珊, 刘子路, 郑爱玲, 等. 基于MobileNetV2和IFPN改进的SSD垃圾实时分类检测方法[J]. 计算机应用, 2022, 42(S1): 106-111. [5] ZHANG Q, ZHANG X, MU X, et al. Recyclable waste image recognition based on deep learning[J]. Resources, Conservation and Recycling, 2021, 171(99): 105636. [6] ZHANG S, CHEN Y M, YANG Z L, et al. Computer vision based two-stage waste recognition-retrieval algorithm for waste classification[J]. Resources, Conservation and Recycling, 2021, 169: 105543. doi: 10.1016/j.resconrec.2021.105543 [7] 高明, 陈玉涵, 张泽慧, 等. 基于新型空间注意力机制和迁移学习的垃圾图像分类算法[J]. 系统工程理论与实践, 2021, 41(2): 498-512. [8] 康庄, 杨杰, 郭濠奇. 基于机器视觉的垃圾自动分类系统设计[J]. 浙江大学学报(工学版), 2020, 54(7): 1272-1280+1307. [9] 马雯, 于炯, 王潇, 等. 基于改进Faster R-CNN的垃圾检测与分类方法[J]. 计算机工程, 2021, 47(8): 294-300. [10] LIN K S, ZHOU T, GAO X F, et al. Deep convolutional neural networks for construction and demolition waste classification: VGGNet structures, cyclical learning rate, and knowledge transfer[J]. Journal of Environmental Management, 2022, 318: 115501. doi: 10.1016/j.jenvman.2022.115501 [11] NOWAKOWSKI P, PAMUA T. Application of deep learning object classifier to improve e-waste collection planning[J]. Waste Management, 2020, 109: 1-9. doi: 10.1016/j.wasman.2020.04.041 [12] 张睿萍, 宁芊, 雷印杰, 等. 基于改进Mask R-CNN的生活垃圾检测[J]. 计算机工程与科学, 2022, 44(11): 2003-2009. [13] LU W S, CHEN J J, XUE F. Using computer vision to recognize composition of construction waste mixtures: A semantic segmentation approach[J]. Resources, Conservation and Recycling, 2022, 178: 106022. doi: 10.1016/j.resconrec.2021.106022 [14] 邢洁洁, 谢定进, 杨然兵, 等. 基于YOLOv5s的农田垃圾轻量化检测方法[J]. 农业工程学报, 2022, 38(19): 153-161. [15] WANG C Y, BOCHKOVSKIY A, LIAO H. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 7464-7475. [16] 赵元龙, 单玉刚, 袁杰. 改进YOLOv7与DeepSORT的佩戴口罩行人跟踪[J]. 计算机工程与应用, 2023, 59(6): 10. [17] WANG Y, FU B, Fu L W, et al. In situ sea cucumber detection across multiple underwater scenes based on convolutional neural networks and image enhancements[J]. Sensors, 2023, 23(4): 2037. doi: 10.3390/s23042037 [18] WANG J Q, CHEN K, LIU Z W, et al. CARAFE: content-aware reassembly of features[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 3007-3016. [19] 陈范凯, 李士心. 改进yolov5的无人机目标检测算法[J]. 计算机工程与应用, 2023, 59(18): 218-225. [20] GENNARI M, FAWCETT R, PRISACARIU V A. DSConv: effificient convolution operator[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 5148-5157. [21] 王浩, 吕晓琪, 谷宇. 基于语义融合与多尺度注意力的红外行人检测[J/OL]. 激光杂志. http://kns.cnki.net/kcms/detail/50.1085.tn.20230213.1802.006.html. [22] 肖振久, 林渤翰, 曲海成. 改进YOLOv7的SAR舰船检测算法[J]. 计算机工程与应用, 2023, 59(15): 243-252. [23] REN S Q, HE K W, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6): 1137-1149. [24] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//European Conference on Computer Vision. Berlin, Germany: Springer, 2016: 21-37. [25] LIU S T, HUANG D, WANG Y H. Receptive field block net for accurate and fast object detection[C]//European Conference on Computer Vision, 2018: 385-400. [26] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the IEEE international conference on computer vision, 2017: 2980-2988. -
 点击查看大图
点击查看大图
计量
- 文章访问数: 2881
- HTML全文浏览数: 2881
- PDF下载数: 122
- 施引文献: 0

























































